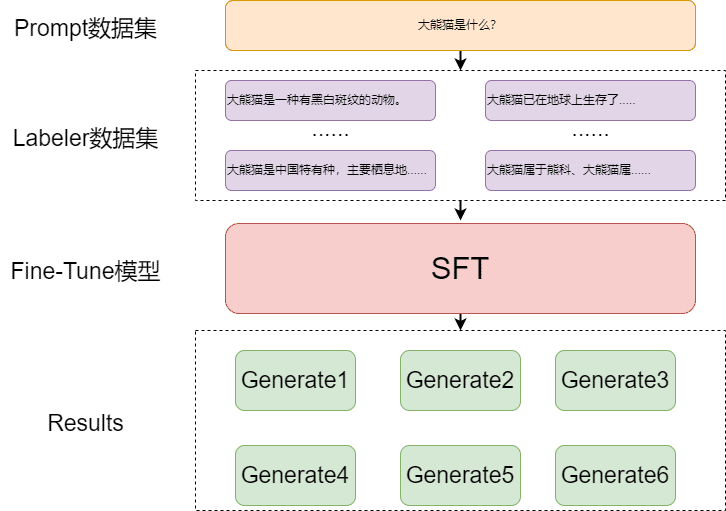
import os.path as osp
index_file = "data/indices/index.json"
if not osp.isfile(index_file):
# 判断是否存在,不存在则创建
index = GPTSimpleVectorIndex.from_documents(documents)
index.save_to_disk(index_file, encoding='utf-8')
else:
# 存在则 load
index = GPTSimpleVectorIndex.load_from_disk(index_file)
import os from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader from llama_index import ( GPTKeywordTableIndex, SimpleDirectoryReader, LLMPredictor, ServiceContext ) from langchain import OpenAI documents = SimpleDirectoryReader('data').load_data() os.environ['OPENAI_API_KEY'] = '设置自己的Key' """ 直接这样可以运行 """ # GPT Index index = GPTSimpleVectorIndex.from_documents(documents) response = index.query("What did the author do growing up?") print(response) """ Response(response='\n\nGrowing up, the author wrote short stories, programmed on an IBM 1401, wrote simple games and a word processor on a TRS-80, studied philosophy in college, learned Lisp, reverse-engineered SHRDLU, wrote a book about Lisp hacking, took art classes at Harvard, and painted still lives in his bedroom at night. He also attended an Accademia where he painted still lives on leftover scraps of ... tover scraps of canvas, which was all I could afford at the time. Painting still lives is different', doc_id='5ba2ade0-0b8c-4ef7-906d-1ca434606232', embedding=None, doc_hash='6a5d8e0ae90c969305717b2ba8d4bc6296336ef595104d8d474abfff99ed64e3', extra_info=None, node_info={'start': 0, 'end': 15198}, relationships={<DocumentRelationship.SOURCE: '1'>: '5c89fa41-6bf8-4181-a9fa-57b66c3aecc1', <DocumentRelationship.NEXT: '3'>: 'a6444b3f-5fc5-4593-8b3d-f04ffb39a6a6'}), score=0.8242781513247005)], extra_info={'5ba2ade0-0b8c-4ef7-906d-1ca434606232': None}) """ """ 自定义模型 """ # # define LLM llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-002")) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) # # build index index = GPTKeywordTableIndex.from_documents(documents, service_context=service_context) response = index.query("What did the author do growing up?") print(response)
Welcome to my digital space! I'm thrilled you've stopped by. Here, you'll find a collection of my thoughts, stories, and insights, all curated with the hope of resonating with you.